Crowdsourcing 101
I recently used crowdsourced experiments for the first time during my Bachelor’s Thesis Project with Prof. Preethi Jyothi. In this blog I will share a few important steps we took to improve the quality of our crowdsourced data. I sincerely thank Prof. Mohit Iyyer for suggesting several useful tips during these experiments, many of which will appear throughout this blog.
Introduction
Google defines crowdsourcing as “the practice of obtaining information or input into a task or project by enlisting the services of a large number of people, either paid or unpaid, typically via the Internet”. With the advent of deep learning, it is getting increasingly important to create high-quality large-scale datasets. This is where crowdsourcing can play an important role.
Crowdsourcing is very common in companies having products with a large userbase. For instance, Google deploys crowdsourcing on a very large scale for obtaining live traffic updates. Facebook can potentially use Messenger conversations for intelligent dialog agents.
Services
Unfortunately, not every organization plays an important role in the day-to-day lives of millions of people. Sometimes, even companies like Google might need very specific datasets which cannot be obtained directly using their products. This is when you turn to dedicated crowdsourcing services where crowdworkers are paid for performing certain tasks. Two popular online crowdsourcing services are Amazon Mechanical Turk and Figure Eight (which was previously known as CrowdFlower). For the result of this article, we will focus on Figure Eight.
Task Setup
In the Figure Eight interface, you begin by adding a number of data rows, often CSV data (in the “DATA” tab). Make sure the first row in the file consists of column titles. Here are Figure Eight’s guidelines on adding data.
The next stage (“DESIGN” tab) requires you to design the actual task. Crowdsourced experiments need to be well-thought of from the crowdworker’s perspective. Good experiments have clear instructions and less ambiguity. MCQ questions are generally preferred over textboxes for more meaningful data collection. For instance, let’s focus on the task of one sentence text classification. If we are specifically interested in sentiment, we should have options like “positive”, “negative”, “neutral” rather than leave a textbox and expect the crowdworker to fill in the sentiment. A person might use positive words “happy”, “joyful” etc. to describe the sentiment instead. For the rest of the article, we will focus on a binary sentiment classification task of one sentence.
The instructions section is quite important, and you could expect most crowdworkers to go through it atleast once during the task. Here are a few tips I learnt from my experience -
- Try to make the title and instructions as unbiased as possible. Sentences like “most of these sentences are unlikely to be positive” should be avoided.
- Instructions should suitably describe the task to be performed. One way to ensure this is to show the task preview to a third person unfamiliar with the research project or problem setting.
- Try to include examples for every possible answer. For instance, in a binary sentiment classification task sample positive, negative and neutral sentences should be presented.
- A “Tips” section should be added to describe unclear questions or options. For instance, pre-processing details should be described if they are significantly going to affect the question statement.
- Use HTML formatting (colors, bolds, italics, underline)
Here is the instruction set I used during my experiments.
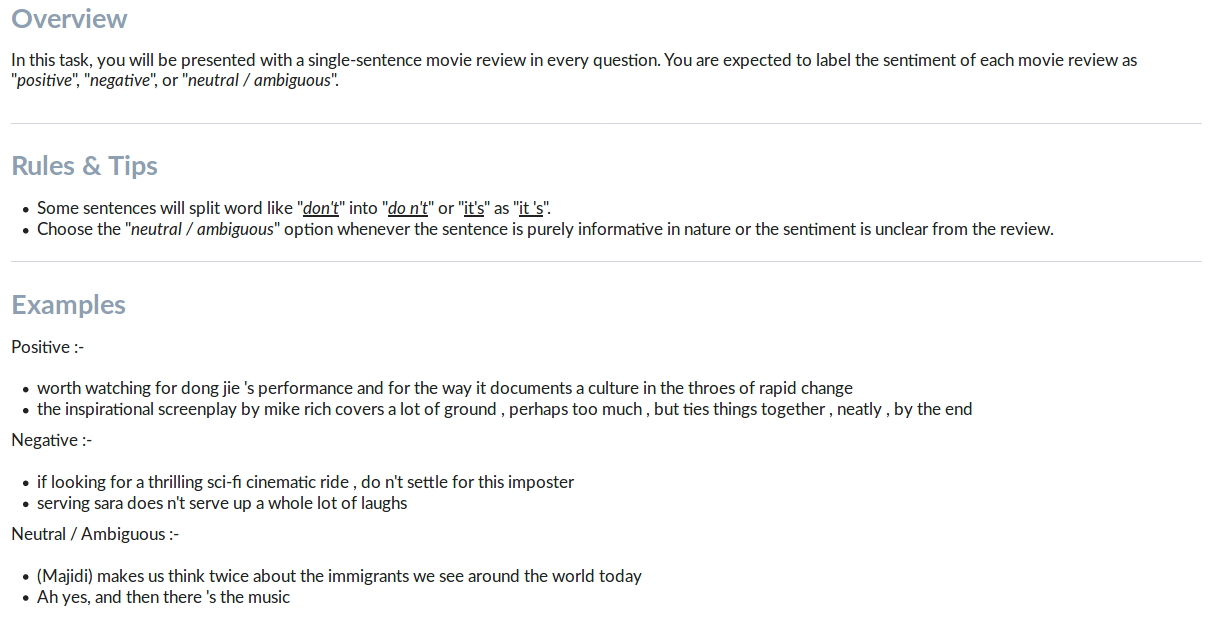
It is a good idea to read Figure Eight’s official Design Tips and Instruction Tips.
Quality Assurance
The next tab (“Quality”) is a quality control measure to ensure that only those people who understand the task correctly are recording their judgements. Every crowdworker appears for a test before starting the task. Throughout the task, the worker is presented with a few hidden test questions. These tests are designed by us, along with a gold set of correct answers (and an option to choose multiple correct answers for ambiguous questions). The crowdworker’s judgements on these test questions determine their competence for the task. Figure Eight rejects workers who fail the initial quiz and marks a user’s judgements as “Untrusted” if he makes several mistakes on subsequent hidden test questions. Figure Eight requires you to create atleast 8 test questions and often recommends you to create more test questions to speed up data collection. Figure Eight has released a couple of guides on Test Questions Best Practices and Monitoring Test Questions.
In my experience, test questions should be very close to the actual task, but as less ambiguous as possible. Ambiguous questions are often contested by crowdworkers and might affect the quality of judgements provided. Very easy test questions are also harmful, since they might be passed by spammers or incompetent crowdworkers (a big problem!). Finally, it’s also a good idea to keep an even distribution of answers so prevent biasing crowdworkers while they perform the actual task.
Keeping good test questions isn’t the only quality assurance technique (and often not enough). A few additional settings can often improve the data collected significantly. Here are a few such settings,
-
Contributor Channels - Keep this at Level 3 if time is not a constraint, but switch to Level 2 if you are in a rush. Level 2 and 3 crowdworkers have a reputation of getting test questions correct (based on their contribution history on Figure Eight) and are less likely to be spammers. Advanced settings include choosing contributor channels (Figure Eight has a guide on this) and language restrictions.
-
Geography - It might help allowing crowdworkers from certain locations only for your experiments. For instance in complicated English NLP tasks, it is a good idea to allow workers only from predominantly English speaking countries. For regional tasks, it makes no sense allowing workers not residing in that region.
-
Quality Control Settings - This setting allows you to keep a minimum time per page (to remove clear spammers) and maximum judgements per worker (to further reduce the effect of bad workers who might slip through). Figure Eight has published a guide for quality control settings.
Launch & Payment
Finally, jobs can be launched in the “Launch” tab on Figure Eight. Figure Eight recommends launching a part of the data (typically 100 rows) as a test run before launching the rest of the data. The “Judgements per Row” setting is again very experiment-specific. Figure Eight offers a “Dynamic Judgements” option, an automated solution to evaluate rows with a less agreement multiple times. (here is their guide)
A very important section here is the price per judgement. It is recommended to pay atleast 7.25$ per hour (minimum wage in USA). One way to convert this to “Price per Judgement” is to perform the task yourself and assess the time it takes per judgement. Generally, a larger payment will cost you significantly more but will speed up the data collection. The difficulty of the task should also be considered. Crowdworkers tend to prefer easier, repetitive tasks (like sentiment classification) rather than more challenging tasks requiring mental effort (like summary writing). Be prepared to pay higher wages to convince crowdworkers that the extra effort is worth it!
Figure Eight has a Jobs Cost FAQ aricle for reference.
Monitoring & Speed
Now that the job has been launched, you can sit back and enjoy the magic of crowdsourcing! The Figure Eight interface is kind-of addicting and you can monitor indvidual contributors as well as assess the overall progress. It is important to keep track of the test questions many workers are marking incorrectly, since they might be ambiguous or mistakes on your part. Workers might contest test questions and you can forgive workers who present a valid explanation for their answers. Finally, some workers might fill a job feedback survey, which is an assessment of the ease, clarity and payment in the job.
Jobs might not run as fast as you need them to. Here are a few useful tricks to speed up your jobs,
- Increase Payment - This is the most reliable way to speed up data collection. However, I could not find a way to increase the payment for data rows that were in progress. Maybe it is a better idea not to order all data rows at once.
- Increase Judgements Per User - This is a helpful trick but might reduce the quality of data collected. This setting can eadjusted under the “Quality Control” setting tab.
- Contributor Channels - Reducing the minimum contributor level (Level 3 to Level 2 for instance) or making the geographic settings more liberal will certainly speed up jobs. Again do this with care to not compromise too much on the quality.
- Internal Workforce - Yes, you can ask your friends to perform the task too, free of cost! While the maximum judgements per user limit would still apply, this is a very reliable way to speed up your crowdsourced experiments. You won’t compromise on quality either, since internal workers need to pass the test too and I am sure you would choose your friends wisely! :)
Figure Eight has several guides on monitoring jobs, a Dashboard Guide, on Auto-Paused Jobs and a guide to convert finalized rows into test questions.
Results
Once jobs complete, there are several detailed reports available for download. (under the “Results” tab). Make sure you adjust the settings to download data in the most suitable format for post-processing. Figure Eight has a nice guide on reports.
I have had a lot of fun in my first crowdsourcing experiment, and I hope to continue doing such experiments during my PhD. If you would like to add something to this article, feel free to get in touch!